Bazy danych -wykład i ćwiczenia.
prowadzący: Michał Hanćkowiak
Literatura.
- Ullman, Widom, "Podstawowy wykład z systemów baz danych", WNT
- Cassel, Eddy, Price, "Access 2002/XP PL dla każdego", Helion
- opis
języka SQL serwera InterBase (pdf)
- opis
języka SQL serwera InterBase (html)
-
opis języka SQL serwera
Postgres 7.2.1
-
PostgreSQL 7.2.1 Documentation
Tematyka wykładu.
- Projektowanie baz danych przy pomocy "diagramów związków encji"
(ERD).
- Model relacyjny baz danych.
- Microsoft Access (w tym: język VBA, obiekty DAO, współpraca Access-u i
serwerów b.d.).
- Serwery baz danych Postgres i InterBase.
- Dostęp do b.d. z internetu (serwer WWW + strony JSP).
................................................................................
................................................................................
Czym jest baza danych.
Czym "aplikacja z baza danych" różni się od zwykłej aplikacji ?
w aplikacjach z bazą danych przechowuje się bardzo duże ilości
danych (nie mieszczące się w pamięci operacyjnej).
Dane --> informacje
baza danych przechowuje dane i pozwala je zamieniać na informacje
-
dane = fakty
-
informacje = przetworzone i pogrupowane dane, przedstawione w postaci
pozwalającej podejmować decyzje i wyciągać wnioski;
przykład 1:
tabela WizytyWSklepie - to są fakty ...
| data |
godzina |
pogoda |
kwota_zakupu |
| 1/10/2003 |
10:00 |
dobra |
15zł |
| 1/10/2003 |
10:15 |
b dobra |
5zł |
| 1/10/2003 |
11:20 |
zła |
100zł |
| 1/10/2003 |
15:00 |
zła |
200zł |
| 2/10/2003 |
14:35 |
dobra |
6zł |
| ..... |
|
|
|
| ..... |
|
|
|
to są informacje ...
| pogoda |
kwota_zakupu |
| dobra |
21zł |
| b dobra |
5zł |
| zła |
300zł |
przykład 2:
w przychodni lekarskiej gromadzi się dane o pacjentach w postaci tabeli:
WizytyPacjentów (nazwisko i imię, pesel, data, kod schorzenia)
potem można zażądać utworzenia takiej tabelki:
| kod schorzenia |
1995 |
1996 |
1997 |
1998 |
1999 |
... |
... |
... |
| C10 |
1000 |
1300 |
|
|
|
|
|
|
| N98 |
3023 |
4567 |
|
|
|
|
|
|
| N78 |
20 |
35 |
|
|
|
|
|
|
| ... |
|
|
|
|
|
|
|
|
DBMS a "aplikacja z bazą danych"
- DBMS = DataBase Management System = system zarządzania bazą danych
- DBMS to "pusta forma" która po napełnieniu treścią staje się "bazą
danych"
- jeśli zautomatyzujemy pewne czynności tak że użytkownik b.d. nie będzie
musiał być specjalistą od b.d. to dostaniemy "aplikację z bazą danych"
- przykłady DBMS :
- Microsoft Access z pakietu Office (silnik b.d. "Jet" + środowisko
graficzne)
- Postgres (tylko serwer b.d)
- InterBase (tylko serwer b.d)
Cechy jakie powinien mieć DBMS:
- Niezawodność zapisu danych - odporność na awarie
- Integralność danych - przechowywane dane muszą spełniać pewne warunki
(wymuszane przez DBMS)
- Sprawność zapytań - wydajne wyszukiwanie danych (tego wymaga "zamiana
danych na informacje")
- Wygodne interfejsy - wygodne sposoby wprowadzania danych (formularze) i
oglądania informacji (raporty), współpraca z innymi programami takimi jak
arkusze kalkulacyjne i edytory tekstów, dostęp przez strony WWW itp ...
- Wielodostęp
- Zabezpieczenia dostępu
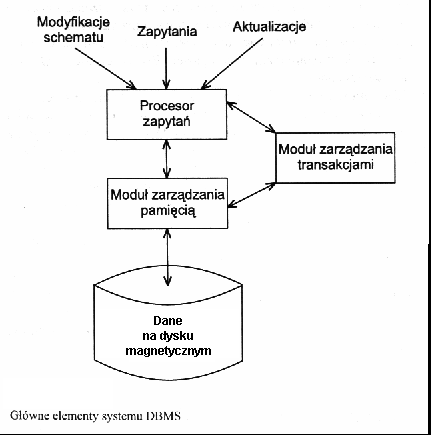
Składniki DBMS:
- Moduł zarządzania pamięcią - obsługuje dysk i bufory w pamięci
operacyjnej, utrzymuje indeksy przyspieszające wyszukiwanie danych
(przykład: wyszukiwanie w książce telefonicznej posort wg nazwisk)
- Procesor zapytań (=kwerend) - generuje odpowiedzi na zapytania (przykład zapytania:
"znajdź wizyty w sklepie gdy pogoda była dobra i godzina > 12:00"); stara się
generować odpowiedzi w możliwie krótkim czasie ! (optymalizacja zapytań);
istnieją także zapytania modyfikujące/aktualizujące dane
- Moduł zarządzania transakcjami - transakcja to kilka modyfikacji danych
które muszą być wykonywane jako całość (tzn albo wszystkie albo żadna);
przykład: przelewy z konta na konto w banku
Baza danych jako element aplikacji klient/serwer (= aplikacji rozproszonej)
- aplikacje 1-rzędowe
- aplikacje 2-rzędowe (klasyczne aplikacje klient/serwer);
przykład:
1 rząd: Access,
2 rząd: serwer baz danych Postgres
(jaki to ma sens ...? odp: wielodostęp)
- aplikacje 3-rzędowe;
przykład - aplikacja 3-rzędowa oparta o WWW:
1 rząd: przeglądarka WWW,
2 rząd: serwer WWW ze stronami JSP lub PHP,
3 rząd: serwer baz danych Postgres
(jaki to ma sens ...?)
przykład - aplikacja 3-rzędowa oparta o obiekty rozproszone:
1 rząd: program "klienta" napisany w języku Java
2 rząd: obiekty rozproszone RMI (dostępne w języku Java)
3 rząd: serwer baz danych Postgres
(jaki to ma sens ...?)
Aplikacja/ architektura 3-rzędowa oparta o WWW:
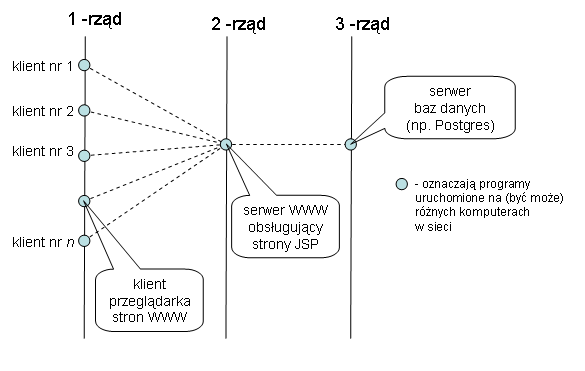
Aplikacja/ architektura 3-rzędowa oparta o
obiekty rozproszone:
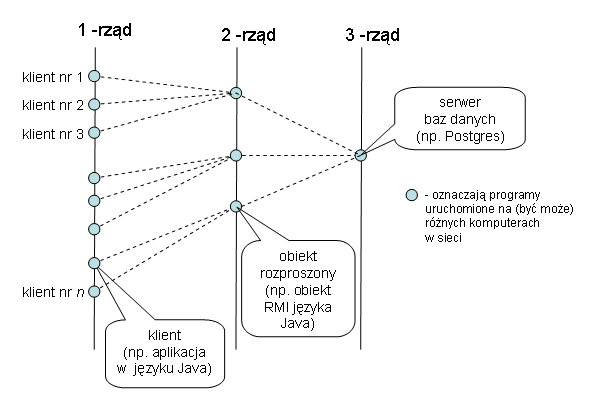
Projektowanie kontra implementacja.
Należy oddzielić projektowanie od implementacji (=tworzenie
relacyjnej b.d.).
Podczas projektowania unika się szczegółów technicznych zaciemniających obraz.
(nieco wyprzedzając materiał ...)
Profesjonalny sposób tworzenia bazy danych jest następujący:
- poznajemy problem który chcemy rozwiązać
- projektujemy; tworzymy diagramy ERD
- zamieniamy ERD na tabele relacyjnej bazy danych
- ulepszamy te tabele (normalizacja)
- definiujemy tabele w DBMS-ie
- tworzymy kwerendy, formularze, raporty w DBMS-ie
- baza danych jest "gotowa" ...
|
Projektowanie przy pomocy diagramów związków encji (ERD).
ERD = Entity Relationship Diagram = diagram związków encji
Przykładowy ERD:
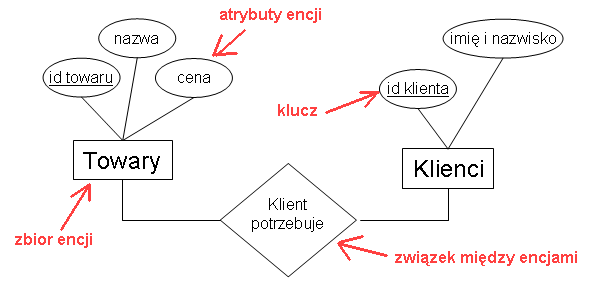
Elementy składowe ERD:
- encje - obiekty "świata rzeczywistego" który
usiłujemy modelować
- zbiory encji - encje tego samego typu; np "Klienci", "Towary"
- atrybuty encji
- związki między encjami
- np związek "Klient potrzebuje" między
zbiorami encji Towary i Klienci; każdemu klientowi odpowiadają towary których
ten klient potrzebuje ... i odwrotnie
- typy związków :
- "jeden do jeden"
- "jeden do wielu" - np związek "Zamówienie czyje" między Zamówienia i
Klienci; każdemu zamówieniu odpowiada dokładnie jeden klient, natomiast każdy
klient może mieć wiele zamówień; (oznaczenie na ERD: strzałka)
- "wiele do wielu" - np związek "Klient potrzebuje" między
Towary i Klienci
- więzy:
- klucz (key) - to atrybut lub atrybuty jednoznacznie wyznaczające encję;
w zbiorze encji nie może być dwóch encji z tą samą wartością klucza; (oznaczenie na ERD:
podkreślenie atrybutu)
- więzy pozwalają wymusić aby encje spełniały pewne warunki ...
Przykłady ERD:
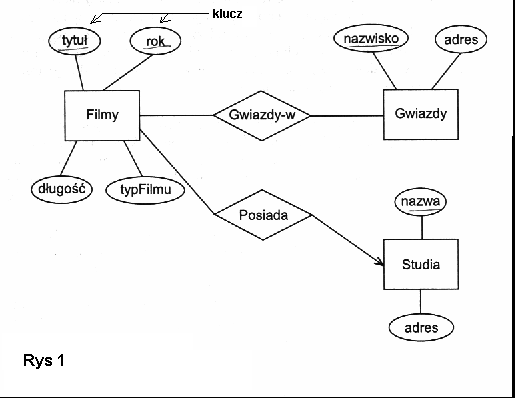
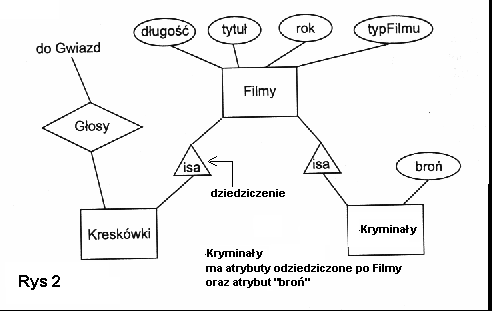
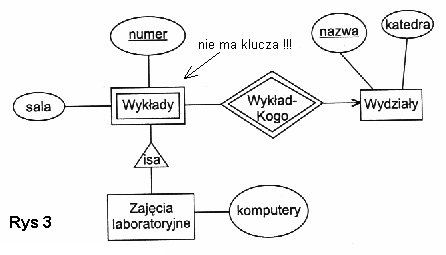
Model relacyjny baz danych.
Podstawowe pojęcia.
| W relacyjnej bazie danych
"dane" przechowuje się w tabelach. |
- tabela (=relacja; stąd "relacyjne bazy danych" !)
| data |
godzina |
pogoda |
kwota_zakupu |
| 1/10/2003 |
10:00 |
dobra |
15zł |
| 1/10/2003 |
10:15 |
b dobra |
5zł |
| 1/10/2003 |
11:20 |
zła |
100zł |
| 1/10/2003 |
15:00 |
zła |
200zł |
| 2/10/2003 |
14:35 |
dobra |
6zł |
| ..... |
|
|
|
| ..... |
|
|
|
- pole tabeli (=atrybut, =kolumna tabeli)
- w powyższej tabeli polami są: data, godzina, pogoda, kwota_zakupu
- pola posiadają nazwy i typy
- liczba pól, ich nazwy i typy są stałe
- przykłady typów pól: tekstowe zmiennej i stałej długości, numeryczne stało i
zmienno pozycyjne, data, czas, data+czas, logiczne, waluta, memo, BLOB/ obiekt
OLE, autonumerowanie
- zbiór atrybutów relacji nazywamy schematem formalnym relacji
- rekord (=krotka, =wiersz tabeli)
- w tabeli nie może być dwóch identycznych rekordów (!)
- liczba rekordów w tabeli jest zmienna
- klucz (key)
- def: klucz to minimalny zbiór pól jednoznacznie wyznaczający
rekord tabeli; słowo "minimalny" oznacza że jeśli usuniemy którekolwiek pole
z klucza to przestanie on wyznaczać jednoznacznie rekordy tabeli
- klucz może się składać z jednego lub więcej pól
- w tabeli może istnieć wiele różnych kluczy
- klucz podstawowy (ang. primary key) - jeden z kluczy tabeli wybrany przez nas
- "klucz" obcy (ang. foreign key) - pole które jest kluczem podstawowym w innej tabeli; w ten
sposób realizuje się związki typu "wiele do jednego" :
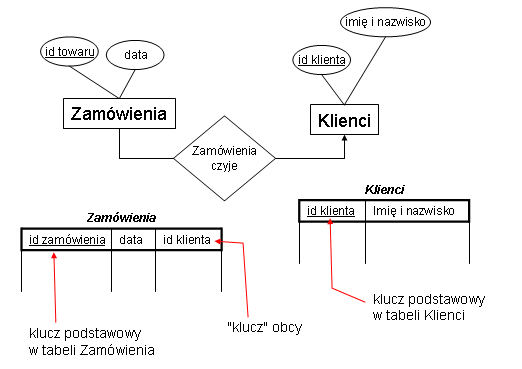
- klucz służy więc do jednoznacznego identyfikowania rekordu tabeli w
innej tabeli
- algebra relacji - na relacjach można wykonywać następujące operacje:
- teoriomnogościowe: suma, przekrój, różnica; (relacje muszą
mieć ten sam zbiór atrybutów)
- selekcja - wybór wierszy spełniających pewien warunek
- rzutowanie - wybór kolumn
- złączenie - iloczyn kartezjański
dwóch tabel, z którego wybiera się wiersze
spełniające pewien warunek
- złączenie naturalne - warunek polega na tym że pola o tych samych
nazwach w obu tabelach muszą mieć identyczne wartości
- złączenie "teta" - warunek jest dowolny
- wyrażenia w algebrze relacji (składające się z tabel i powyższych
operacji) nazywamy kwerendami
- kwerendy służą do "wyciągania" informacji z tabel (czyli zamiany
danych w
tabelkach na informacje użyteczne dla użytkownika)
- oznaczenia operacji w algebrze relacji:
selekcja - tabela{warunek}
rzutowanie - tabela[lista pól]
złączenie naturalne - tabela1*tabela2
Przykład:
tabela Klienci :
| nazwa |
adres |
id klienta |
| Jan Kowalski1 |
qqq1 |
1 |
| Jan Kowalski2 |
qqq2 |
2 |
tutaj [id klienta] jest kluczem
tabela Zamowienia :
| towar |
ilosc |
data |
id klienta |
| masło |
5 |
1/10/2003 |
1 |
| chleb |
15 |
2/10/2003 |
2 |
| wino |
3 |
10/10/2003 |
1 |
tutaj kluczem może być [data] i [id klienta], przy założeniu że każdy klient
może złożyć co najwyżej jedno zamówienie w każdym dniu; [id klienta] jest
"kluczem" obcym
złączenie naturalne tabel Klienci i Zamówienia :
| nazwa |
adres |
id klienta |
towar |
ilosc |
data |
| Jan Kowalski1 |
qqq1 |
1 |
masło |
5 |
1/10/2003 |
| Jan Kowalski1 |
qqq1 |
1 |
wino |
3 |
10/10/2003 |
| Jan Kowalski2 |
qqq2 |
2 |
chleb |
15 |
2/10/2003 |
z powyższej tabeli mogę wybrać wiersze spełniające warunek : data >=
#2/10/2003# (to jest selekcja)
mogę wybrać interesujące mnie pola : nazwa, towar, ilosc (to jest rzutowanie)
dostanę wtedy następującą tabelkę wynikową:
| nazwa |
towar |
ilosc |
| Jan Kowalski1 |
wino |
3 |
| Jan Kowalski2 |
chleb |
15 |
tabelka powyższa jest wynikiem "złożenia" operacji złączenia, selekcji i
rzutowania;
innymi słowy jest wartością pewnego wyrażenia w algebrze relacji;
mianowicie takiego:
((Klienci*Zamowienia){data>=#2/10/2003#})[nazwa,towar,ilosc]
(koniec przykładu)
- indeksy
- jeśli założymy indeks na pole "nazwa" to tabela jakby zostanie posortowana
wg pola nazwa, a wtedy będzie można szybko znajdować rekordy z określoną wartością w polu "nazwa"
(zasada książki telefonicznej)
- ogólnie, indeksy pozwalają przyspieszyć wyszukiwanie danych w tabelach
- są oparte na jednym polu lub większej liczbie pól
- specjalny rodzaj indeksów to indeksy unikalne/ unikatowe - nie
zezwala się żeby w tabeli były dwa rekordy z tą samą wartością pola na które
nałożono indeks unikalny (wyjaśnić co ma wspólnego szybkie wyszukiwanie z
unikalnością)
- indeksy przyspieszają operacje wymagające wyszukiwań/sortowań zgodnych z początkową częścią klucza indeksowania
- indeksy są konieczne dla:
- klucza podstawowego
- realizacji tzw więzów jednoznaczności (indeksy
unikalne)
- wskazane dla:
- kluczy obcych
- wartości używanych przy złączeniach
- wartości używanych do sortowania
- przeciwwskazane dla kolumn bardzo często modyfikowanych
- transakcje
- w ramach transakcji można wykonać grupę operacji na danych jako całość, tj
na zasadzie "wszystkie albo żadna" (albo wszystkie się uda wykonać albo
żadnej)
- przykład: przelew z kontoA na kontoB; realizuje się to tak:
1 operacja: kontoA = kontoA - kwota_przelewu
2 operacja: kontoB = kontoB + kwota_przelewu
- polecenie rozpoczynające transakcję ???
- polecenie zatwierdzające transakcję "commit"
- polecenie odwołujące transakcję "rollback"
- więzy
- klucz (key) - patrz def klucza -
to jest najważniejszy rodzaj więzu
- więzy jednoznaczności (single-value constraints) - nie może
być dwóch rekordów z taką samą wartością danego pola; realizuje się je przez
indeksy unikalne
- więzy integralności referencyjnej (referential integrity constraints) - np
dla każdego Zamówienia musi istnieć Klient
- więzy domenowe (domain constraints) - wartość pola musi
należeć do pewnego zbioru zwanego "domeną"
- więzy zasadnicze (general constraints) - dowolny warunek który musi być
spełniony przez wszystkie rekordy tabeli
- więzy pozwalają wymusić aby dane w tabelach spełniały pewne warunki - nie
da się zmodyfikować danych lub wprowadzić nowych danych, gdyby naruszało to te
warunki ...
Kwerendy.
Kwerendy pozwalają "wyciągać" informacje z bazy danych (innymi słowy:
zamieniać dane na informacje).
Kwerenda to wyrażenie algebry relacji zazwyczaj zapisane w języku
QBE lub SQL.
QBE (= Query By Example), jest to "wizualny" sposób zapisu kwerend.
SQL (=Structured Query Language), jest to tekstowy sposób zapisu kwerend.
Języki SQL i QBE są równoważne.
Języki SQL/QBE wykraczają daleko poza możliwości algebry relacji ...
Przykład tej samej kwerendy zapisanej na różne
sposoby:
Kwerenda zapisana oznaczeniami z algebry relacji:
((Klienci*Zamowienia){imie i nazwisko='Jan Kowalski1'})[imie i nazwisko,
ilosc, data]
Kwerenda zapisana w języku QBE:
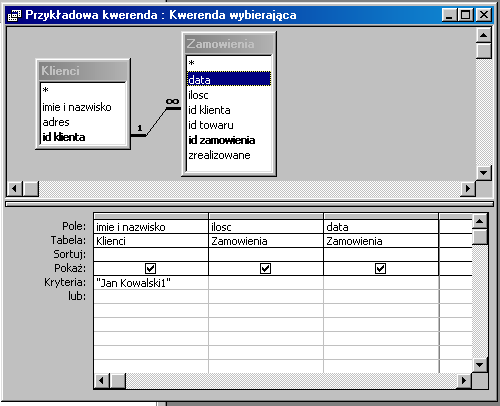
Kwerenda zapisana w języku SQL:
SELECT Klienci.[imie i nazwisko], Zamowienia.ilosc,
Zamowienia.data
FROM Klienci INNER JOIN Zamowienia ON
Klienci.[id klienta] = Zamowienia.[id klienta]
WHERE Klienci.[imie i nazwisko]="Jan
Kowalski1";
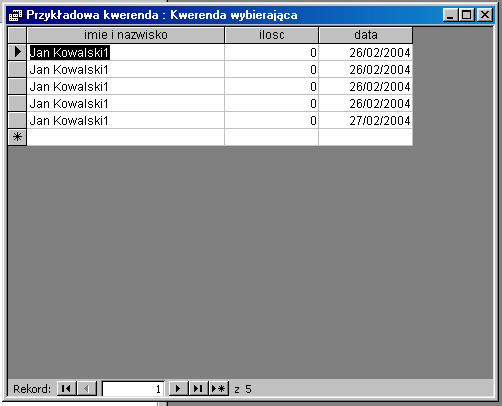
Wynik działania kwerendy:
Inne proste przykłady SQL-a:
// zakładamy że dysponujemy tabelami Klienci i Zamówienia
// o następujących schematach formalnych:
// Klienci (nazwa, adres, id klienta)
// Zamówienia (towar, ilosc, data, id klienta)
np1:
select * from Klienci;
// wyświetla wszystkie pola i wszystkie rekordy tabeli Klienci
np2:
select nazwa, [id klienta] from Klienci;
// wyświetla tylko pola nazwa i [id klienta]
// nawiasy [] ze względu na spacje w nazwie
// (UWAGA: to jest specyficzne dla Access-u !)
// rzutowanie
np3:
select nazwa, adres, towar
from Klienci inner join Zamowienia on Klienci.[id klienta]=Zamowienia.[id klienta]
where data > #2/10/2003#
// wyświetla nazwy klientów, ich adresy i towary
// zamówione po 2/10/2003;
// rzutowanie + selekcja + złączenie (naturalne)
np4:
select nazwa, adres, towar
from Klienci, Zamowienia
where (data > #2/10/2003#) and (Klienci.[id klienta] = Zamowienia.[id klienta])
// alternatywne rozwiązanie ...
// w poniższych przykładach SQL wychodzi poza algebrę relacji !!!
np5:
update Zamowienia set ilosc=ilosc+1 where [id klienta]=2
// polecenie modyfikuje tabele Zamówienia;
// zwiększa "ilosc" o 1 dla wszystkich zamówień
// pochodzących od klienta z [id klienta]=2
np6:
select towar, SUM(ilosc) as [Suma ilosci]
from Zamowienia
group by towar
order by SUM(ilosc)
// dla każdego towaru oblicza łączną ilość zamówień;
// grupujemy rekordy tabeli wg pola "towar",
// i dla każdej grupy obliczamy sumę pól "ilosc";
// kolumna pokazująca łączną ilość na nazwę "Suma ilosci";
// wynik jest posortowany rosnąco wg wartości sum